Duplicate Content: So vermeiden Sie doppelte Inhalte

Über das Duplicate Content-Problem wurde in der Welt der Suchmaschinenoptimierung schon sehr viel philosophiert und geschrieben. Es gibt leider immer noch zahlreiche Unwahrheiten zu diesem Thema. Wir zeigen Ihnen in diesem Ratgeber alles, was Sie über Duplicate Content (DC) wissen sollten.
Sie lernen unter anderem kennen,
- was der Unterschied zwischen internen und externen DC ist,
- was Google in Bezug auf DC nicht gerne sieht,
- wie Sie doppelte Inhalte richtig kennzeichnen
- und welche Strategien es zur Vermeidung von doppelten Inhalten gibt.
Der Mythos “Duplicate Content”: Was hat es damit auf sich?
Um Nutzern die bestmöglichen Informationen auf eine Anfrage präsentieren zu können, liefern Suchmaschinen wie Google innerhalb von Bruchteilen einer Sekunde eine ganze Sammlung an Ergebnissen zu einem Suchbegriff zurück. Gibt es mehrere Webseiten, die den identischen Content anbieten, versucht Google das Original zu bestimmen und in den Suchergebnissen anzuzeigen. Schließlich dürfte es dem Nutzer nicht gerade weiterhelfen, wenn er an Position 2, 3 und 4 den gleichen Content zu einem bestimmten Thema findet.
Die Suchmaschine filtert die doppelten Inhalte quasi aus. Das hat allerdings nichts mit einer Penalty (Strafe) wegen Duplicate Content zu tun. Es ist vielmehr ein Problem aus SEO-Sicht. Google möchte den Nutzern das bestmögliche Nutzererlebnis bieten, daher macht es keinen Sinn, mehrmals den gleichen Inhalt zu listen, nur weil er auf unterschiedlichen Domains publiziert wurde.
Was ist der Unterschied: Interner und Extener Duplicate Content
Wenn doppelte Inhalte innerhalb der selben Domain/Website vorkommen, spricht man von internem Duplicate Content oder auch On-Site Duplicate Content. Ein Beispiel dafür sind Inhalte eines Artikels, der auf mehreren URLs der gleichen Domain erreichbar ist. Es könnte aber auch ein Produkt sein, dass beispielsweise unter www.domain.de/blumen.html und www.domain.de/produkte.html verfügbar ist. In manchen Content-Management-Systemen gibt es auch spezielle Seiten für den Druck eines Beitrages. Diese werden oft unter einer anderen URL bereitgestellt und bieten eine für den Ausdruck optimierte Darstellung. Da der Inhalt auf zwei URLs erreichbar ist, entsteht automatisch ein Duplicate-Content-Problem, welches über eine korrekte Kanonisierung beider URLs direkt vermieden werden kann.
Externer Duplicate Content bedeutet, dass Duplikate auf unterschiedlichen Domains im WWW existieren. Das kommt häufig bei Content-Spiegelungen oder Pressemitteilungen vor. Stichwort Content Syndication: Wenn Nachrichtenagenturen beispielsweise Mitteilungen herausgeben und kleinere Zeitungen diese aus den Content-Pools eins zu eins übernehmen, entsteht Duplicate Content, weil die Inhalte auf mehreren Webseiten identisch sind.
Ursachen für internen DC:
- Produkte auf mehreren URLs erreichbar
- Keine kanonische URL festgelegt
- Druckansichten von Artikeln mit eigener URL
Ursachen für externen DC:
- Content-Syndikation (z. B. PR)
- Website unter mehreren Domains erreichbar
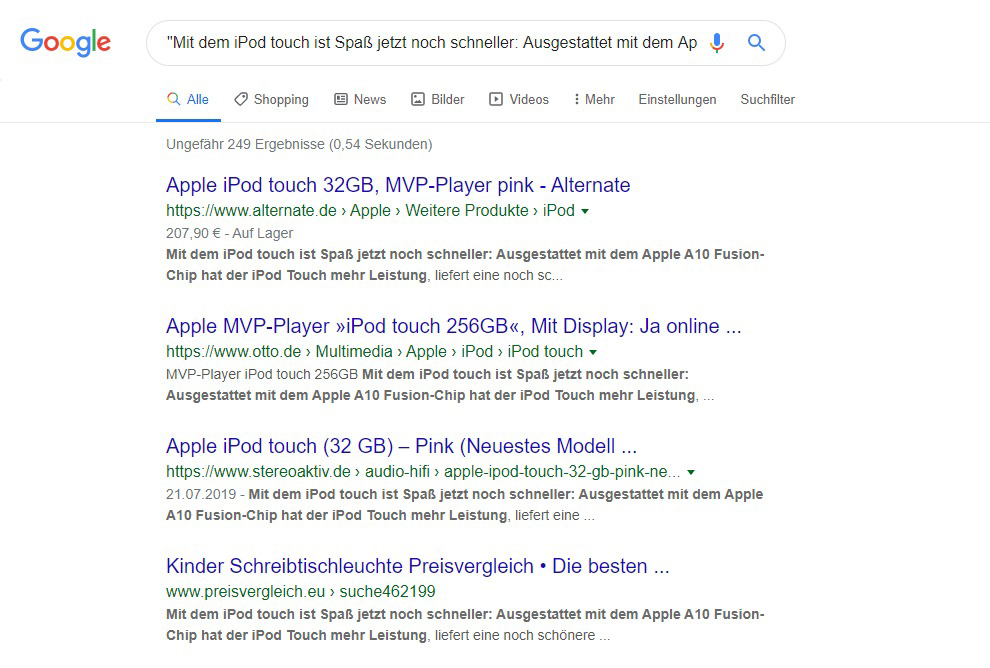
Häufig sind Produkttexte, die eins zu eins vom Hersteller übernommen wurden, Grund für den Duplicate Content.Screenshot: google.com / FLYERALARM Digital
Duplicate Content ist aber nicht gleich Duplicate Content. Auch Matt Cuts von Google hat dazu vor einigen Jahren in einem YouTube-Video Stellung bezogen. Duplicate Content ist nicht per se schlecht. Es gibt genügend gute Gründe für die doppelte Verbreitung von denselben Inhalten. Auch bei Pressemitteilungen ist das so.
Versucht man allerdings, das Google Ranking absichtlich durch Content Duplizierung zu manipulieren, kann es durchaus vorkommen, dass Google Korrekturen am Suchindex der entsprechenden Website vornimmt. Erkennt Google, dass eine Website bewusst den Google Algorithmus täuscht, werden Websites niedriger eingestuft und fliegen im schlimmsten Fall komplett aus dem Suchindex von Google.
Der ein oder andere wird sich jetzt sicher die Frage stellen, was das für die Hauptnavigation oder den Seitenabschluss (Footer) bedeutet. Schließlich ist dieser Website-Bereich ja auf jeder Unterseite nahezu identisch. Ist das schon ein Duplicate Content Problem? Zum Glück nicht! Nur umfangreiche Inhaltsblöcke werden von Google als Duplicate Content erkannt. Das ist beispielsweise der Text eines Blog-Artikels als Teil des Primary-Content einer Website.
Alle anderen Elemente, die sich auf Unterseiten wiederholen, werden in diesem Zusammenhang auch als Boilerplate bezeichnet. Im Grunde genommen wäre dies auch Duplicate Content aber Suchsysteme wie Google können diese Inhalte sehr schnell identifizieren und entsprechend bewerten.
Tipps zur Vermeidung von Duplicate Content
Jeder Websitebetreiber ist selbst für die Vermeidung von Duplicate-Content verantwortlich und kann dafür sorgen, dass Besucher nur die Inhalte sehen, die sie sehen sollen.
Content-Syndikation: Duplicate Content vermeiden
Wenn Sie Ihren Content (z. B. Pressemeldungen) auf andere Websites syndizieren, zeigt Google immer die bei der jeweiligen Suche relevanteste Seite für den Nutzer an. Das ist jedoch nicht immer die bevorzugte Variante. Durch einen Link zur Originalmeldung kann man auf den einzelnen Webseiten dafür sorgen, dass Google dies erkennt und entsprechend bewertet. Alternativ kann man die Verwerter Ihrer Pressemeldungen auch höflich darum bitten, per Meta-Tag “noindex” die Indexierung in Suchmaschinen zu unterbinden. Wie aber bereits erläutert, muss Content-Syndikation nicht unbedingt ein Problem sein.
Website in unterschiedlichen Sprachen
Ihre Website ist in verschiedenen Sprachen verfügbar? Auch das ist kein Problem für Suchmaschinen, wenn es richtig gekennzeichnet wurde. Google stellt dafür das hreflang-Attribut zur Verfügung. So kann man dem Googlebot mitteilen, dass es sich um eine Sprachvariante handelt und die Inhalte nicht als Duplicate-Content zu werten sind. Je nach Region bzw. Aufenthaltsort des Nutzers, wird Google dann die für den Nutzer relevante Sprachvariante anzeigen in den Suchergebnissen.
HTML-Markup für die richtige Kennzeichnung (Beispiel):
<head> <title>Widgets, Inc</title> <link rel="alternate" hreflang="en-gb" href="http://en-gb.example.com/page.html" /> <link rel="alternate" hreflang="en-us" href="http://en-us.example.com/page.html" /> <link rel="alternate" hreflang="en" href="http://en.example.com/page.html" /> <link rel="alternate" hreflang="de" href="http://de.example.com/page.html" /> <link rel="alternate" hreflang="x-default" href="http://www.example.com/" /> </head>
Alternativ empfiehlt Google auch für landesspezifische Inhalte den Einsatz einer eigenen Top-Level-Domain. Laut der Google Search Console-Hilfe weißt http://www.domain.de eher auf landesspezifischen Content für Deutschland hin als http://www.domain.com/de. Natürlich ist nicht alles in Stein gemeißelt, was von Google kommuniziert wird. Unserer Meinung nach ist es zum Beispiel unter http://www.domain.com/de und http://www.domain.de/fr genau so ersichtlich, dass es sich um Inhalte für Deutschland bzw. Frankreich handelt.
Autorisierte Domain in der Search Console festlegen
Jeder Website-Besitzer kann seine eigenen Domains mit der kostenlosen Google Search Console verwalten. Neben wertvollen Insights rund um Suchvolumen und Klicks, kann man auch Sitemaps einreichen oder die bevorzugte Domain für die Darstellung in der Google Suche wählen. Angenommen Ihre Website ist unter http://www.domain.de und http://domain.de erreichbar und Sie möchten die Version mit www-Präfix als bevorzugte Domain festlegen, können Sie dies ganz einfach in der Search Console durchführen.
So weiß Google, welche Domain die Hauptdomain ist. Im Idealfall ist dann auf Ihrer Website auch keine Seite mehr ohne das www-Präfix abrufbar. Für alle nicht autorisierten Seiten können Sie das sogenannte Canonical-Tag verwenden. Damit weisen Sie den Googlebot an, welches Dokument das Original ist.
Original per Canonical-Tag kennzeichnen
Wenn mehrere Inhalte unter verschiedenen URLs abrufbar sind, können Sie das Original per Canonical-Tag kennzeichnen. So weiß die Suchmaschine genau, wie Sie das Dokument handhaben soll. Wie das genau funktioniert, soll am Beispiel eines Artikels und der dazugehörigen Version für den Druck erläutert werden. Der Artikel ist abrufbar unter http://www.domain.de/artikel.html. Es existiert aber auch eine Duplette in Form einer Druckansicht unter http://www.domain.de/druckansicht/artikel.html.
In allen existierenden Varianten, sollte folgende Zeile im HTML-Code gesetzt werden:
<link rel="canonical" href="http://www.domain.de/artikel.html" />
Platzieren Sie diese Zeile im <head>-Bereich Ihrer Website. Suchmaschinen erkennen dann, wo das Original zu finden ist und welche Beziehung die verschiedenen Varianten untereinander haben.